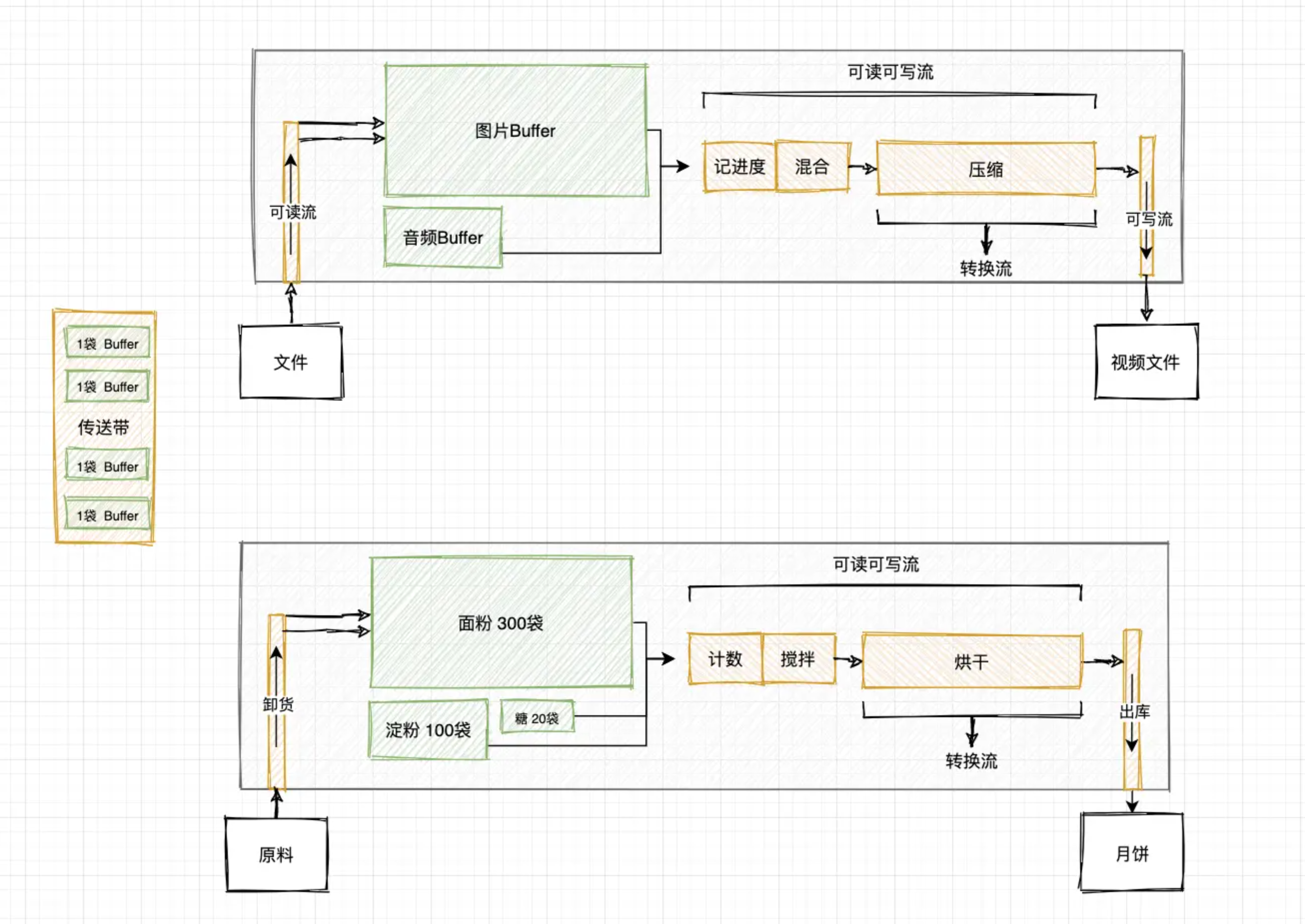
Stream流
计算机中所有的内容(文字、图片、视频、数字等)最终都会使用二进制来表示。流是一种用于处理二进制数据的抽象接口,Nodejs提供了Stream类处理程序中的流数据。
TIP
流可以是可读的、可写的,或者两者兼之(双工)的,Nodejs中所有的流都是EventEmitter的实例。
流的类型
Nodejs提供了四种基本类型的流:
- Readable Stream:可读流,消费数据源的抽象。示例如下:
- 客户端的
HTPP响应 - 文件系统的读取流
zlibcrypto加密- TCP套接字
process.stdin
- 客户端的
- Writable Stream:可写流,写入目标的抽象。
- 客户端上的
HTTP请求 - 在服务器上的
HTTP响应 - 文件系统写入流
zlib解压缩crypto加密- TCP套接字
process.stdout,process.stderr
- 客户端上的
- Duplex Stream:双工流,可读可写,同时实现
Readable、Writable接口的流。zlib解压缩crypto加密- TCP套接字
- Transform Stream:特殊的双工流,在读写过程中对数据进行转换,转换流也要实现读写接口,并需要实现额外的
_transform方法。zlib解压缩crypto加密
进制
JavaScript 中提供的进制表示方法有四种:十进制、二进制、十六进制、八进制。
主要使用不同的前缀来区分:
- 十进制(Decimal):
JavaScript默认数字进制,取值0-9,不用前缀 - 二进制(Binary):前缀
0b,取值0和1 - 十六进制(Hexadecimal):前缀
0x,取值0~9和a-f - 八进制(Octal):前缀
0o,取值0-8
JavaScript提供了原生函数,来对十进制和其他进制之间的转换。
其他转十进制
- parseInt(str,radix)
- 隐式转换
+ - Number()
jsparseInt('1111', 2) // 15 parseInt('1234', 8) // 668 parseInt('18af', 16) // 6319 parseInt('1111') // 1111 +'0b11100' // 28 +'0o33' // 27 +'0x33' //51 Number('0b11100') // 28 Number('0o33') // 27 Number('0x33') //51十进制转其他
- Number.prototype.toString(radix)
js(15).toString(2) // 1111 (585).toString(8) // 1111 (4369).toString(16) // 1111 (11.25).toString(2) // 1011.01
缓冲区
ai对于缓存区的理解
缓冲区是一块内存区域,充当着“中间商”的角色,主要用于临时存储数据,以协调不同设备、进程或系统之间的数据传输速度差异。
Buffer 类是 JavaScript Uint8Array 类的子类,分配固定大小的内存空间。缓冲区的声明需要指定大小,也就是说一旦实例化了buffer申请了内存空间,就无法在原来的内存上进行扩容。
alloc
分配固定
size的Buffer。jsconst { Buffer } = require("node:buffer") const buf = Buffer.alloc(20)form
从字符串、数组、
ArrayBuffer、其他Buffer实例等创建一个Buffer。jsconst {Buffer} = require('node:buffer') const bufStr = Buffer.from(["1"]); const bufArr = Buffer.from("1"); const bufBuf = Buffer.from(bufStr);slicesubarray实例方法,该方法会返回一个新的
Buffer,截取的是内存,也就是浅拷贝。jsconst { Buffer } = require('node:buffer') const buf = Buffer.from('hello world', 'utf8') const subBuf = buf.subarray(0, 5) console.log(subBuf.toString()) // hello;TIP
slice接口已被弃用,请使用subarray替代。 该方法是在Buffer的原型上,需要通过实例去调用。copy
将数据从
source缓冲区复制到target缓冲区。jsconst {Buffer} = require('node:buffer') const buf = Buffer.from('hello world', 'utf8') const copyBuf = Buffer.alloc(5) buf.copy(copyBuf,0,0,5) console.log(copyBuf.toString()) // hello;TIP
模拟实现
copy:jsBuffer.prototype.myCopy = function(target, targetStart, start, end) { for (let i = start; i < end; i++) { target[targetStart++] = this[i] } }concat
拼接两个
Buffer,合并成为一个Buffer,不指定长度默认为合并Buffer的长度总和。jsconst {Buffer} = require('node:buffer') const buf = Buffer.from('hello world', 'utf8') const buf1 = Buffer.from('你好啊 李银河', 'utf8') const buf2 = Buffer.concat([buf, buf1], buf.length + buf1.length) console.log(buf2.toString()) // hello world你好啊 李银河;TIP
模拟实现
concat:jsBuffer.myConcat = function(list, length) { length = length || list.reduce((prev, next) => prev + next.length, 0) const buf = Buffer.alloc(length) let offset = 0 list.forEach(item => { item.copy(buf, offset) offset += item.length }) return buf }length
返回
Buffer缓冲区的字节长度。jsconst {Buffer} = require('node:buffer') const buf = Buffer.from('hello world', 'utf8') console.log(buf.length); // 11isBuffer
判断一个数据是否为
bufferjsconst {Buffer} = require('node:buffer') const buf = Buffer.from('hello world', 'utf8') console.log(Buffer.isBuffer(buf)); // true
文件读写
当读取文件时,数据从文件系统流向内存中,将文件的数据中读取出来,储存在内存中。此时的数据流向是从文件系统流向内存,对于内存来说这种操作更多是写入。
内存是存在大小限制的,当操作的数据量过大,超过了内存的量时,会造成“淹没可用内存”,造成程序无法正常运行。
Nodejs在读取文件的操作时,建议读取文件的大小在64kb以下(写入的速度和读取为 1:4 ),对于超出建议大小的文件,可以结合缓冲区,从文件系统读一点再写一点到内存中最后在程序中表示。
举个复制大文件 🌰 :
const fs = require("node:fs");
const path = require("node:path");
const { Buffer } = require("node:buffer");
function copy(source, target, callback) {
const buf = Buffer.alloc(400);
// 1.打开源文件
// 权限位:0o666表示此文件拥有可读可写的权限
fs.open(source, "r", 0o666, (err, rfd) => {
if (err) return callback(err);
// 2.打开目标文件
fs.open(target, "w", (err, wfd) => {
if (err) return callback(err);
// 3.记录读写偏移量
let rPos = 0;
let wPos = 0;
function close() {
let i = 0;
function done() {
if (++i === 2) {
return callback();
}
}
fs.close(rfd, done);
fs.close(wfd, done);
}
// 异步串行写入
function next() {
// 每次读取源文件的数据,往目标文件写入。
// bytesRead表示实际读取的字节长度
fs.read(rfd, buf, 0, 3, rPos, (err, bytesRead) => {
if (err) return callback(err);
if (bytesRead === 0) {
return close();
} else {
// 偏移量每次增加上实际读取的偏移量,就是文件最末尾的位置
rPos += bytesRead;
fs.write(wfd, buf, 0, bytesRead, wPos, (err, written) => {
if (err) return callback(err);
wPos += written;
next();
});
}
});
}
next();
});
});
}
copy(
path.resolve(__dirname, "Obsidian.dmg"),
path.resolve(__dirname, "Obsidian-copy.dmg"),
() => {
console.log("拷贝完成");
}
);上面的例子可以看到缺点,存在回调地狱,开关文件的操作和读写的操作没有关系。
其实Nodejs已经提供了这种能力,结合events模块和fs模块——fs.createReadStream、fs.createWriteStream,这两个API接口实现了Stream.Readable、Stream.Writable类的定义接口类型。
改造一下 🌰:
const fs = require("node:fs");
const path = require("node:path");
const rs = fs.createReadStream(path.resolve(__dirname, "Obsidian.dmg"));
const ws = fs.createWriteStream(path.resolve(__dirname, "Obsidian-copy.dmg"));
rs.on("data", (chunk) => {
const flag = ws.write(chunk);
if (!flag) {
rs.pause();
}
});
ws.on("drain", () => {
rs.resume();
});
rs.on("end", () => {
ws.end();
});
ws.on("finish", () => {
console.log("拷贝完成!");
});- 在写入数据
ws.write(chunk)时,会返回一个标识,写入长度 >= highWaterMark时会返回false,表示当前的缓冲区已满,应停止写入数据。 drain事件会在flag = false时触发,表示当前缓冲区已经被清空,可以继续写入。- 最后当
ws.end()调用后,会触发finish事件,已经写入完成。
这样就能控制写入的速度大于内存读取的速度,避免内存中数据堆积过多,同时确保数据能够高效地写入目标存储。
fs的文件流API实际上是继承了可读流和可写流的定义接口并重写了内部方法Readable——_read()、Writable——_write()。
类似下面的继承重写:
class Parent {
say() {
this._say();
}
_say() {
console.log("parent say method");
}
}
class Child extends Parent {
constructor() {
super();
}
_say() {
console.log("child say method");
}
}
const c = new Child();
c.say(); // "child say method"双工流
双工流(Duplex)是同时实现了Stream.Readable、Stream.Writable类的定义接口的流。
const { Duplex } = require("stream");
const duplexStream = new Duplex({
write(chunk, encoding, next) {
const reversed = chunk.toString().split("").reverse().join("");
this.push(reversed); // 将反转后的数据推送到可读端
next();
},
read() {},
});
// 读取终端控制台输入
process.stdin.on("data", (chunk) => {
duplexStream.write(chunk);
});
duplexStream.on("data", (chunk) => {
console.log("duplexStream:", chunk.toString());
});转换流
转换流是一种特殊的双工流,对输入转换后再输出,比如加解密、nestjs的管道函数、解压缩流等。
转换流的不必实现读、写方法,只需要实现转换方法,它已经将两者结合起来,具有write的功能,也有read的功能。
这是一个简单的大小写转换流,将输入内容转换为大写格式再进行输出:
const { Transform } = require("stream");
const transformStream = new Transform({
transform(chunk, encoding, callback) {
this.push(chunk.toString().toLocaleUpperCase());
callback();
},
});
process.stdin.pipe(transformStream).pipe(process.stdout);流的管道
流的管道是指用于将可读流的输出直接链接到可写流的输入,实现数据从管道的一端自动流向管道的另一端。这是为了简化流之间的数据传输流程,链式操作支持多个转换流之间的串联。
基础用法:文件读写的例子改造成结合管道的用法
const fs = require("node:fs");
const path = require("node:path");
const rs = fs.createReadStream(path.resolve(__dirname, "Obsidian.dmg"));
const ws = fs.createWriteStream(path.resolve(__dirname, "Obsidian-copy.dmg"));
rs.pipe(ws).on("finish", () => {
console.log("写入完成");
});流的错误处理
每个流都是EventEmitter的实例,所以在管道流的链式处理过程中,某个流要是发生了错误,可以使用事件触发器的error事件去捕获错误。
rs.pipe(ws)
.on("error", (err) => {
console.log("error:", err);
})
.on("finish", () => {
console.log("写入完成");
});【更推荐】:也可以使用pipeline()方法替换该事件自动处理,避免未处理的错误导致程序崩坏:
pipeline(rs, ws, (err) => {
if (err) {
return console.error("管道操作失败:", err);
}
console.log("管道操作完成!");
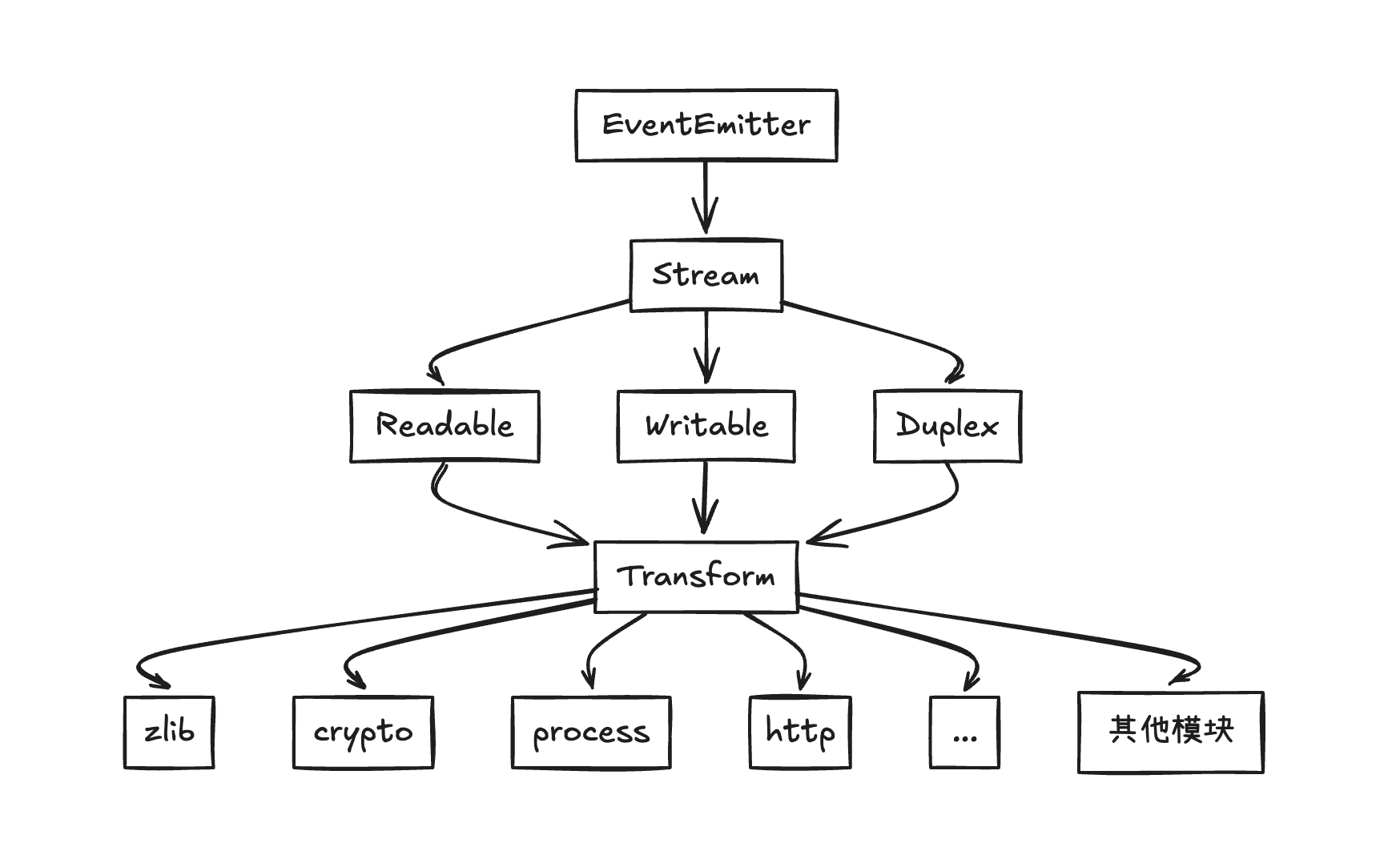
});内置模块关系
Nodejs内置的流模块覆盖了文件、网络、加密、压缩、进程通信等场景。
关系示意图:
自定义流
手写可读流
- 可读流在打开文件时,触发
open事件 - 监听
data事件,读取流数据 - 读取文件结束时,触发
end事件
const EventEmitter = require("node:events");
const fs = require("node:fs");
const { Buffer } = require("node:buffer");
const defaultOptions = {
flags: "r",
encoding: null,
fd: undefined,
mode: 0o666,
autoClose: true,
emitClose: true,
start: 0,
highWaterMark: 64 * 1024, // 读取缓冲区大小默认64k
};
const mappingOptions = function (options, defaultOptions = {}) {
for (const key in { ...options, ...defaultOptions }) {
this[key] = options[key] || defaultOptions[key];
}
};
class ReadStream extends EventEmitter {
constructor(path, options) {
super();
mappingOptions.call(this, { path, ...options }, defaultOptions);
// 当前是否正在读取文件,给暂停、恢复方法使用的
this.flowing = false;
this.position = this.start;
this.on("newListener", (type) => {
if (type === "data") {
// 当data被触发时,说明正在读取文件
this.flowing = true;
this.read();
}
});
this.open();
}
// 横向切面
// - 捕获错误
// - 关闭文件:根据 this.fd 可以判断当前是否打开了文件,并触发 close 事件
destroyed(err) {
if (this.fd && this.autoClose) {
fs.close(this.fd, () => this.emitClose && this.emit("close"));
}
if (err) {
return this.emit("error", err);
}
}
// 1.当实例化时,会触发open事件,并存储fd
open() {
fs.open(this.path, (err, fd) => {
if (err) {
return this.destroyed(err);
}
this.fd = fd;
this.emit("open", fd);
});
}
// 2.打开文件后就是读取数据,触发data事件 —— 监听newListener的data,有就触发read读取
// - 根据highWaterMark大小从文件中读取数据,并暂存到缓冲区(涉及到Buffer的使用)
read() {
// 第一步,拿到当前打开的文件描述符,由于newListener是同步监听的,data是异步触发的
// 所以保证准确获取到fd,我们可以在拿不到fd的情况,触发open事件,在回调中是一定能拿到fd的,然后再次read读取即可
// 但不是每次都需要重新打开文件的,因为在回调的再次读取是一定能拿到fd,所以只要触发一次即可
if (typeof this.fd !== "number") {
return this.once("open", () => this.read());
}
// buffer的大小取决于highWaterMark
const buf = Buffer.alloc(this.highWaterMark);
// 维护每次应该读取的长度
// 假设传递了end参数,而highWaterMark又不能整除时
// 我们需要控制读取的长度刚好到文件的末尾
const shouldReadNumber = this.end ? Math.min(this.end - this.position + 1, this.highWaterMark) : this.highWaterMark;
// 开始读取文件
fs.read(this.fd, buf, 0, shouldReadNumber, this.position, (err, bytesRead) => {
if (err) {
return this.destroyed(err);
}
if (bytesRead === 0) {
// 否则就是读完了,触发end事件
this.emit("end");
} else {
// bytesRead表示当前读取的长度,也就是>0的情况会持续触发data事件
//同时还需要维护游标,每次读到多少都需要相加
this.position += bytesRead;
this.emit("data", buf.subarray(0, bytesRead));
if (this.flowing) {
this.read();
}
}
});
}
// 3.暂停读取文件
pause() {
this.flowing = false;
}
// 4.恢复读取
// - 只有在暂停时才需要恢复
resume() {
if (!this.flowing) {
this.flowing = true;
this.read();
}
}
}
const rs = new ReadStream(filepath, { highWaterMark: 4 });
rs.on("data", (chunk) => {
console.log("chunk:", chunk);
});手写可读流实现,学习events模块的更多应用,学习多个异步嵌套使用发布订阅进行解耦。
手写可写流
可写流在写入数据调用write()方法时,并不会立即将所有数据写入到文件中,而是将第一次内容先写入,后面的内容的会往缓冲里面存放,等再次调用callback(),剩下的内容才会从缓存区拿出来往文件写入。
调用write()方法时,会返回一个标识,这个标识会在写入长度>=highWaterMark时返回false,表示当前缓冲区已经满了,应该停止写入数据。
当标识为false时,堆积在缓冲区的数据会被清空,会触发可写流的独有事件——drain,这个事件触发了也就说明当前可以继续写入数据。
write()的结果告知是否可以继续写入数据drain事件的触发依赖于write()的结果,结果为false时触发drain事件触发说明当前缓冲区已被清空,可以继续写入数据- 可写流被实例化会触发
open事件
这样就能控制写入的速度大于内存读取的速度,避免内存中数据堆积过多,同时确保数据能够高效地写入目标存储。
const EventEmitter = require("node:events");
const fs = require("node:fs");
const { Buffer } = require("node:buffer");
const path = require("node:path");
const defaultOptions = {
flags: "w",
mode: 0o666,
autoClose: true,
emitClose: true,
encoding: "utf-8",
start: 0,
highWaterMark: 16 * 1024, // 写入默认是16k
};
const writePath = path.resolve(__dirname, "text.txt");
const mappingOptions = function (options, defaultOptions = {}) {
for (const key in { ...options, ...defaultOptions }) {
this[key] = options[key] || defaultOptions[key];
}
};
class WriteStream extends EventEmitter {
constructor(path, options) {
super();
mappingOptions.call(this, { ...options, path }, defaultOptions);
this.offset = this.start;
this.fd = undefined;
// 缓存区,除第一次外都写入该内存中
this.cache = [];
this.writing = false; // 默认情况不写入
this.needDrain = false; // 只有当写入的个数达到或超过highWaterMark并清空缓冲区后触发的drain事件的标识
this.len = 0; // 当前次写入的长度,会与highWaterMark做比较,得到flag以及是否会触发drain事件
// 1. 实例化对象必定会触发open事件
this.open();
}
destroyed(err) {
if (err) {
return this.emit("error", err);
}
}
open() {
fs.open(this.path, this.flags, this.mode, (err, fd) => {
if (err) {
return this.destroyed(err);
}
this.fd = fd;
this.emit("open", fd);
});
}
// 2. 用户调用的write事件,但并不是真正的写入操作,所以这里不能直接打开文件
write(chunk, encoding = this.encoding, callback = () => {}) {
// 将chunk全部转换成buffer
chunk = Buffer.isBuffer(chunk) ? chunk : Buffer.from(chunk);
this.len += chunk.length;
// 维护flag
let res = this.len >= this.highWaterMark; // 写入的个数超过预期,说明当前缓冲区已满
this.needDrain = res; // 写入完毕后是否需要触发drain
const callbackFn = () => {
callback();
this.clearBuffer();
};
// writing第一次写入这个值必定是false,所以会触发if分支,并且将内容写入到文件中
if (!this.writing) {
// 真正写入内容
this.writing = true;
this._write(chunk, encoding, callbackFn);
} else {
// 往缓冲区内存
this.cache.push({
chunk,
encoding,
callback: callbackFn,
});
}
return !res;
}
// 清除缓存区
clearBuffer() {
let cacheObj = this.cache.shift();
if (cacheObj) {
// 有值接着写
this._write(cacheObj.chunk, cacheObj.encoding, cacheObj.callback);
} else {
// 全部写入完毕
this.writing = false;
if (this.needDrain) {
this.needDrain = false;
this.emit("drain");
}
}
}
// 真正写入文件的方法
// withClearCacheCallback包含清空缓存区的回调
_write(chunk, encoding, withClearCacheCallback) {
// 判断文件是否打开
if (typeof this.fd !== "number") {
return this.once("open", () => this._write(chunk, encoding, withClearCacheCallback));
}
fs.write(this.fd, chunk, 0, chunk.length, this.offset, (err, written) => {
this.len -= written;
this.offset += written;
withClearCacheCallback();
});
}
}
const ws = new WriteStream(writePath, { highWaterMark: 1 });
ws.write("abc");手写可写流同样学习了事件触发器events的应用,以及学习处理多个异步串行的任务。
自定义双工流
双工流实现了Readable、Writable定义接口的流,实际上是不需要重头到位将双工流重写一遍,只需要继承可读可写的接口,并重写方法。
const { Duplex } = require("node:stream");
class MyDuplex extends Duplex {
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
_read(size) {
this.push("I'm data");
this.push(null);
}
}
const myDuplex = new MyDuplex();
myDuplex.on("data", (chunk) => {
console.log(chunk.toString());
});
myDuplex.write("Hello");
myDuplex.end();自定义转换流
特殊的双工流,我们不必实现读取或写入方法,只需要实现一个转换方法,它将两者结合起来。
这是一个简单的变换流,它将您转换为大写格式后输入的任何内容回送回来:
const { Transform } = require("node:stream");
class MyTransform extends Transform {
constructor() {
super();
}
_transform(chunk, encoding, callback) {
this.push(chunk.toString().toUpperCase());
callback();
}
}
const myTransform = new MyTransform();
myTransform.write("a");
myTransform.on("data", (chunk) => {
console.log(chunk.toString());
});案例一:大文件分割
创建一个程序,将大文件分割成多个小文件:
- 允许用户指定分割的大小
- 使用流处理以减少内存使用
- 为每个分割的文件生成唯一的名称
- 显示分割进度
案例二:HTTP请求限流器
创建一个Transform流,用于限制HTTP请求的速率:
- 控制每秒处理的请求数
- 实现令牌桶或漏桶算法
- 提供可配置的限流参数
- 处理突发流量
案例三:日志处理
创建一个日志处理系统,包含以下功能:
- 从多个源读取日志(文件、HTTP请求等)
- 解析不同格式的日志
- 过滤和转换日志内容
- 将处理后的日志写入到不同的目标(文件、数据库、控制台等)
- 实现日志轮转功能
- 处理错误和异常情况